
谙流 ASK 技术解析(一):秒级扩容
谙流 ASK 是谙流团队自主研发的国产新一代云原生流平台,与 Apache Kafka 100% 协议兼容,全栈自主可控,专注私有化部署与行业场景赋能。
传统Kafka存储之殇
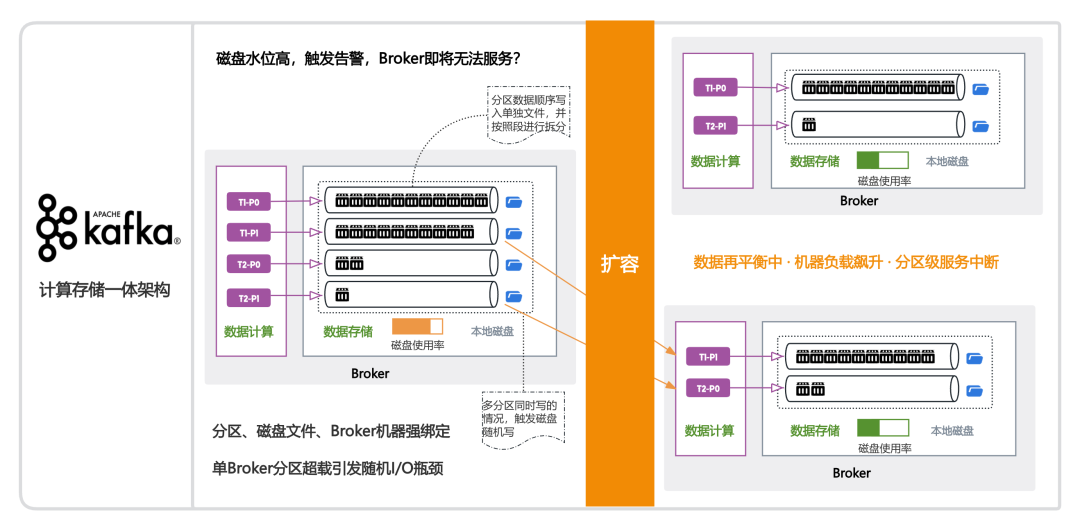
IO模型缺陷
每个分区对应独立文件,采用单分区异步批量顺序写机制。当多分区并发写入时,IO 模式逐渐退化为随机写。若将 Kafka 刷盘条数调至极小值(如高可靠性场景),随机写问题将显著加剧(机械盘顺序写性能可达随机写的100倍),导致性能断崖式下跌[1]。此为 Broker 节点无法承载过多分区的核心根因。
分区-机器绑定困局
存算一体架构限制:分区与特定Broker机器绑定。随着业务增长,部分Broker可能出现分区数据空间占用不均——少数分区占据大量磁盘空间。为保障业务稳定,需将大分区迁移至低负载Broker。
扩容引发二次灾难:当业务流量激增导致磁盘即将写满时,必须扩容。由于分区与机器强绑定,扩容需将高负载Broker的分区全量迁移至新Broker。此过程将进一步加剧本已高负载集群的压力,引发连锁故障。
正是由于Kafka的存算一体架构设计,实际运维中高要求场景需遵循两条核心准则,Broker节点磁盘使用率控制在60%以内,避免瞬时写满引发服务中断;严控集群Topic总规模,规避后续扩容[2]与故障定位困难。
ASK 分片存储模型
为彻底解决传统架构中分区数据与特定物理机器的强绑定问题,ASK引入分片存储模型,将分区数据切割为逻辑分片(Shard1-6),并全域分布式存储于集群共享存储池中(Storage1-3),其核心设计如下:
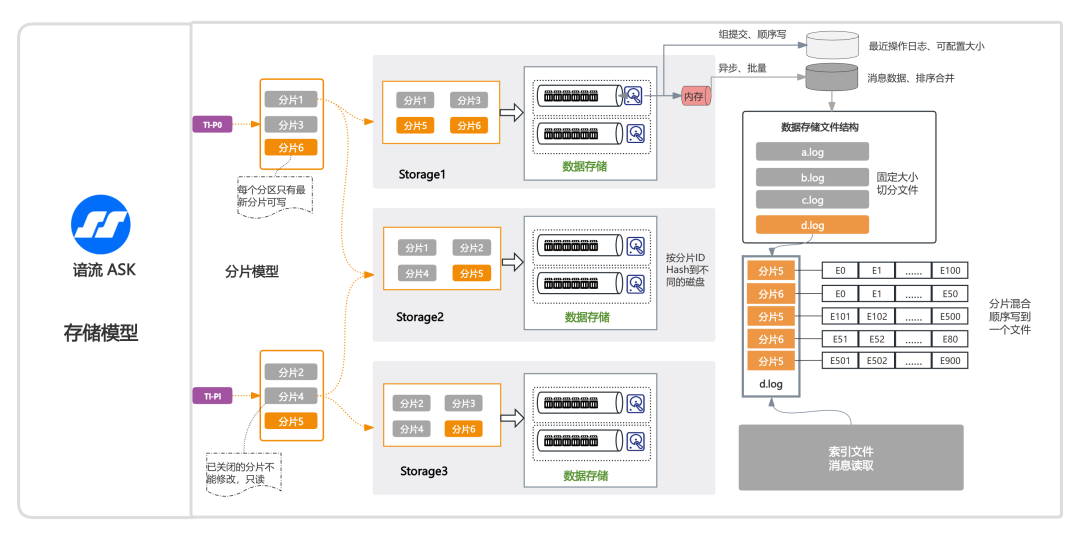
在谙流 ASK 存储架构中,分区(Partition)- 分片(Ledger)- 存储节点(Storage Node)的关联关系如下:
- 分片是分布式存储的最小逻辑单元,其 ID 由 Storage 分配,保证全局单调递增。
- 分区与分片映射示例
- 一个Topic(如两分区 P0/P1)。
- 每个分区绑定一组递增的分片ID(如P0: L1→L3→L6,P1: L2→L4→L5)。
- 仅最新分片可写(如 L6/L5),其他分片关闭后只读不可修改。
3. 分片写入规则
- 副本数由Topic级别参数replication.factor定义(默认3副本)。
- 目标存储节点通过动态负载均衡算法选择。
分片数据在 Storage Node 组织方式如下:
- 读写IO物理隔离
- 操作日志(WAL):使用独立的磁盘设备,全局顺序写入,采用组提交机制合并小IO以提升效率。副本写入操作日志成功即代表该副本写入成功。操作日志仅需保留近期数据,主要用于节点异常退出时的恢复,可根据实际场景配置为同步写入、异步写入或不写入(三种模式可选)。
- 消息数据:用户数据会写入其它磁盘或磁盘阵列中,采用异步、批量方式刷盘以提高性能。消息读请求主要从这部分磁盘读取,从而实现了消息读写路径的物理分离。
2. 消息数据文件结构(图中 a.log, b.log...)
- 混合存储:先将多个分片的数据写入内存,并对该分片内的数据进行排序和合并,当达到一定条件后批量写入文件中。
- 文件切割:单个文件达到阈值时(例如文件大小到达2G),则生成新文件(a.log→b.log)。
3. 索引管理
为更高效地读取数据,建立了索引机制,快速根据分片读取消息内容。
凭借出色的性能保障机制,ASK 以更周密的数据读取机制实现了比 Apache Kafka 更优的性能表现。这一点我们会在技术解析的后续文章中进行详细分析。
ASK存算分离架构
上面介绍了分布式存储服务,其整体存算分离架构主要包括 Metadata 服务和 Broker 服务,三者共同构成如下三层架构:
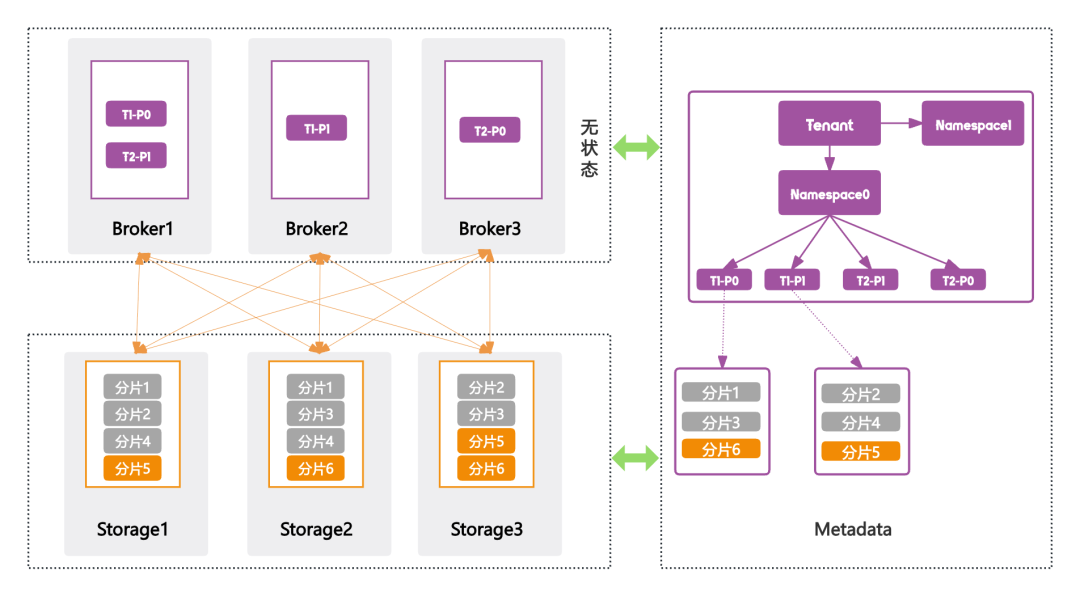
1. Metadata层(元数据控制层)
- 存储租户(Tenant)、命名空间(Namespace)、Topic、分区(Partition)的定义和映射关系。
- 存储分区(Partition)、分片(Ledger)的映射关系。
- 存储分片(Ledger)的元数据,例如分片的记录数、副本数、副本所在的Storage Node信息等。
2. Broker层(无状态计算层)
- Broker 节点本身不存储业务数据,启动时通过与元数据服务交互,动态加载 Topic 与分区的路由映射关系。
- Broker 集群通过一种简单快速的方式选出Leader,由其统一管理分区分配及负载均衡策略。
- 每个分区仅绑定至单一 Broker 节点,读写请求由该节点直接对接 Storage 层处理。
3. Storage层(持久化存储层)
负责真正的数据持久化存储
ASK秒级扩容
在介绍完 ASK 的分片存储模型和存算分离架构后,接下来我们将看看如何实现快速扩容。
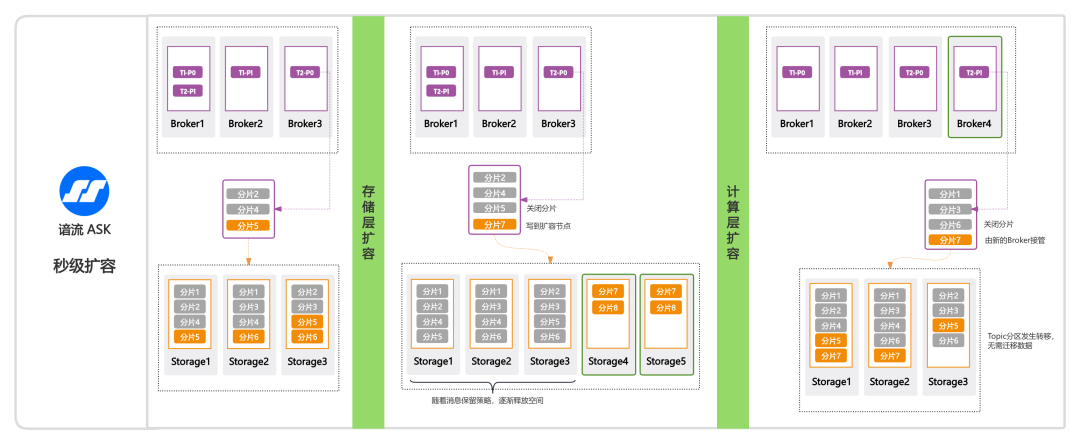
存储层扩容(左侧→中部)
- 紧急扩容:当存储层磁盘空间不足时,Storage 节点从 3个(Storage1/2/3) 快速扩容至 5个(新增Storage4/5),新节点加入后 Broker 秒级探测,并依据调度算法将新分片定向写入扩容节点(如分片7→Storage4/5)。
- 日常扩容:当分片达到阈值(如5000条或4小时),系统自动关闭当前分片并创建新分片,新数据优先写入扩容节点(如分片8→Storage4)。
- 空间释放:旧节点数据依赖消息保留策略渐进回收空间(非立即删除),避免瞬时IO压力。
计算层扩容(中部→右侧)
- 分区接管:新增 Broker 节点(如Broker4)后,系统自动触发负载均衡,将指定分片(如分片7)迁移至新节点。迁移流程如下:o 关闭写入:原 Broker 停止对该分片的写入(元数据标记为关闭状态)。o 路由切换:分片绑定至新 Broker,由其加载分片元数据并接管读写流量。
- 秒级转移:全流程秒级完成,客户端自动重连新节点,业务零感知。
- 零数据迁移:仅更新元数据路由,Storage 层数据物理位置不变,规避迁移开销。
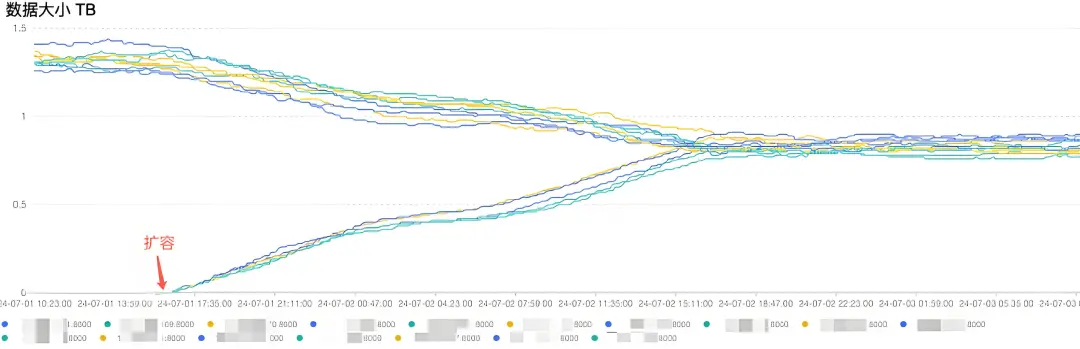
下面是某实际客户的扩容的效果图:
- 双向奔赴:扩容后,新节快速承接新增写入流量,各存储节点间的负载快速趋于均衡。同时,存储集群的数据分布随时间推移逐步收敛,最终达成容量平衡状态,全过程无需人工干预,无数据迁移。
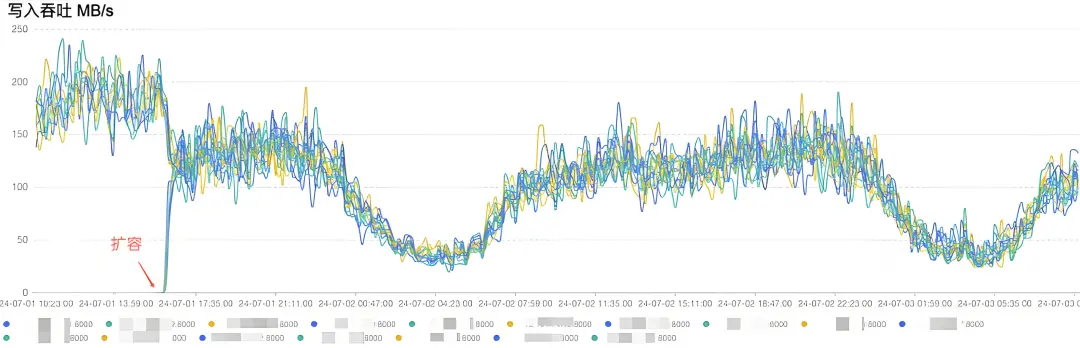
- 平滑稳定:整个集群在扩容的过程中,生产消息服务平滑无感。
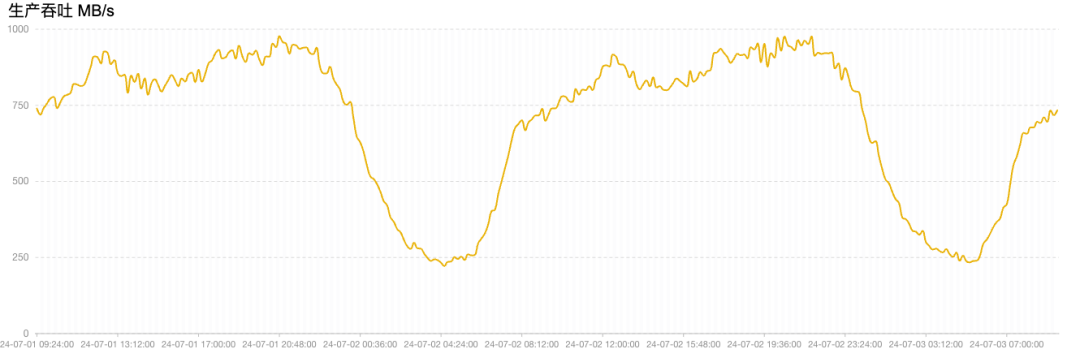
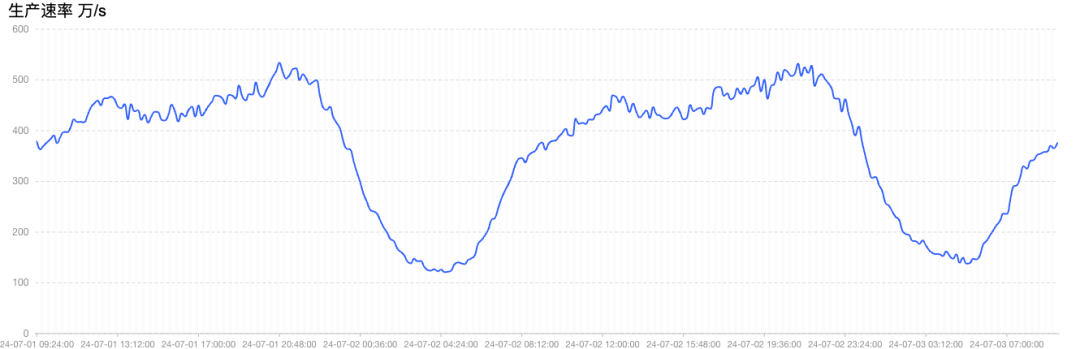
总结
谙流 ASK 以国产化云原生架构,重塑 Apache Kafka 核心引擎:
- 破传统之殇:独创分片存储模型,彻底解耦分区与物理机器的强绑定困局;
- 立三层之优:Metadata-Broker-Storage 存算分离架构,实现计算、存储、调度的独立弹性;
- 证秒级之效:存储层秒级扩容免迁移,计算层分区无感切换零中断,性能与容量实现「双向奔赴」。
这就是 ASK —— 协议 100% 兼容,稳定性大跃升,让企业在私有化场景下告别 Apache Kafka 的扩容之痛,驾驭流数据再无后顾之忧。
联系我们,获取更多产品及服务信息。
关注公众号
订阅精彩内容


推荐阅读
谙流 ASK:告别 Kafka 运维救火,解锁流数据自治时代
谙流 ASK 是谙流团队自主研发的国产新一代云原生流平台,与 Apache Kafka 100% 协议兼容,全栈自主可控,专注私有化部署与行业场景赋能。
谙流 ASK 技术解析(二):高性能低延迟
谙流 ASK 是谙流团队自主研发的国产新一代云原生流平台,与 Apache Kafka 100% 协议兼容,全栈自主可控,专注私有化部署与行业场景赋能。
谙流 ASK 技术解析(三):冷热数据自治分层
谙流 ASK 是谙流团队自主研发的国产新一代云原生流平台,与 Apache Kafka 100% 协议兼容,全栈自主可控,专注私有化部署与行业场景赋能。
端到端加密,多团队数据安全共享

谙流科技由 Apache Pulsar 和 Apache BookKeeper 的核心人员倾力打造,专注提供云原生消息队列(MQ)和流处理(Streaming)基础软件及解决方案,打造统一消息流 PaaS 平台,助力企业数字化新质生产力。
关注谙流,获取最新动态
